Wie können Kreative ihre Arbeiten vor der Nutzung fürs KI-Training schützen?
Der Urheberrechtstreit, in dem gerade Fotograf Robert Kneschke vor dem Hamburger Landgericht gegen LAION e.V. klagt, geht uns alle an.

Am 11. Juli fand endlich die erste Verhandlung der schon ewig anhängigen Klage des Stockbildfotografen Robert Kneschke gegen LAION 5B statt – eine Datenbank, in der ein Hamburger Lehrer die direkten Links zu 5.8 Milliarden Fotos aufgelistet hatte, teils inklusive Bildbeschreibungen. Die Bildersammlung des LAION e.V. kam unter anderem beim Training von Stable Diffusion zum Einsatz.
Die Details der Klage sind komplex. Wir wollen an dieser Stelle nur auf die Erkenntnisse eingehen, die man aus der Verhandlung für den aktuellen Schutz von Bildern vor der Weiterverwertung durch generative KI-Modelle mitnehmen konnte.
Dabei sollten alle Kreativen bedenken, dass nicht nur der Schutz von Stockfotos zur Debatte steht, sondern auch das Urheberrecht für jedes andere Foto, jede Illustration und jedes grafische Design.
In der Juristerei muss alles ja sehr genau zugehen, deshalb konzentriert sich die Klage aber auf ein ganz bestimmtes Bild, das (ganz unspektakulär …) einige Rentner beim Training zeigt. LAION hatte über die Stockbildagentur Bigstock auf die frei zugängliche Layout-Version mit Wasserzeichen zugegriffen und die Datei auch kurzfristig heruntergeladen, um automatisiert zu überprüfen, ob die Beschreibung dem Inhalt des später nur verlinkten und dann von Dritten weiter genutzten Bildes entsprach. Die Kläger (mit Sebastian Deubelli als Fachanwalt für Urheber- und Medienrecht) sehen das als nicht rechtens an, da die Bildagentur in ihren Nutzungsbedingungen durchaus klar und deutlich auf Urheberrechte hingewiesen hatte.
Dem Gericht reichte das nicht. Daten-Mining ist ja per se heute erlaubt, wer bestimmten Crawlern den Zugriff verweigern wolle, müsse für einen entsprechenden robots.txt sorgen. Es obliegt den Klägern jetzt nachzuprüfen, ob Bigstock (eine Tochterfirma von Shutterstock) im Jahr 2021 das Bildmaterial tatsächlich schon in dieser Weise hätte schützen müssen. Wohlgemerkt zu einem Zeitpunkt, als noch kaum jemand ans Thema KI-Training dachte. Entscheidend ist hier Paragraf 44b des Urheberrechtgesetzes, der u.a. folgendes besagt:
»Ein Nutzungsvorbehalt bei online zugänglichen Werken ist nur dann wirksam, wenn er in maschinenlesbarer Form erfolgt.«
Diesen Satz sollten sich alle Kreativen wohl an die Wand nageln … oder den Schutz ihrer wie auch immer gearteten Werke mehr oder minder vergessen. Ersteres heisst nämlich nicht nur die eigene Site mit solchen maschinenlesbaren, genau spezifizierten Anti-Crawler-Dateien vor unerwünschten Zugriffen zu bewahren. Letztlich müssten für einen solchen Schutz aber auch die Kunden sorgen, die dann ihrerseits die Bilder/grafischen Arbeiten im Netz veröffentlichen.
Das Rentner-Foto zum Beispiel, um das es in der gerichtlichen Auseinandersetzung geht, hat Robert Kneschke hundertfach verkauft. Deshalb findet es sich auch mehrfach in der LAION-Datenbank – wahrscheinlich heruntergeladen aus verschiedenen Quellen. Sinnvoller erscheint darum die neue Opt-Out-Option in den IPTC-Metadaten jeder einzelnen Bilddatei (siehe unten).
Für den 27. September hat das Hamburger Landgericht einen weiteren Verhandlungstermin anberaumt. Ob es bis dahin endgültig entscheidungsreif ist, sei allerdings noch nicht sicher. Der Fall könnte später noch Bundesgerichtshof oder Europäischen Gerichtshof beschäftigen.
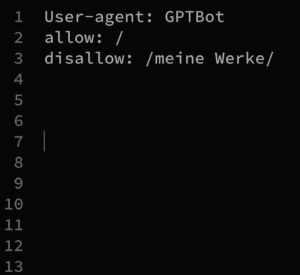
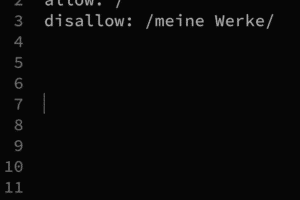
Wie sieht ein robots.txt aus?
Das kann man sich zum Beispiel bei der »New York Times« ansehen unter https://www.nytimes.com/robots.txt (das Muster der URL funktioniert auch bei jeder anderen Site, die solche Vorkehrungen trifft).
Unter »#Disallow Rules« sind einige der wichtigsten aktuellen Crawler gelistet, die die »New York Times« von sich fernhalten möchte. Den Text kann man gegebenenfalls einfach in den eigenen robots.txt kopieren. Das ist urheberrechtlich unproblematisch 😉 Und immer mal wieder aktualisieren!
Schutz von Bilddateien in den Metadaten
Der IPTC (International Press Telecommunications Council) hat außerdem 2023 in den Metadaten, die man jedem Foto für seinen Weg durch Netz mitgeben kann, eine neue Opt-Out-Möglichkeit eingerichtet.
Die Metadaten enthalten ja schon lange Copyright-Informationen. Jetzt gibt es zudem ein Feld namens »Data-Mining«. Dort kann man eintragen, welche Art von Nutzung man erlaubt. Alle Infos dazu gibt es in diesem Artikel auf der IPTC-Website. Bei Klick auf das dort gezeigte Beispielbild kann man sehen, wie die Metadaten dazu aussehen – im Feld »Data-Mining« wird mit dem Eintrag »DMI-PROHIBITED-GENAIMLTRAINING« die Nutzung fürs Training generativer KIs verboten.
Metadaten lassen sich in Bilddateien bekanntlich in Adobe-Programmen wie Photoshop, Lightroom oder Illustrator hinzufügen – mehr Infos dazu findet man hier.
Das könnte dich auch interessieren