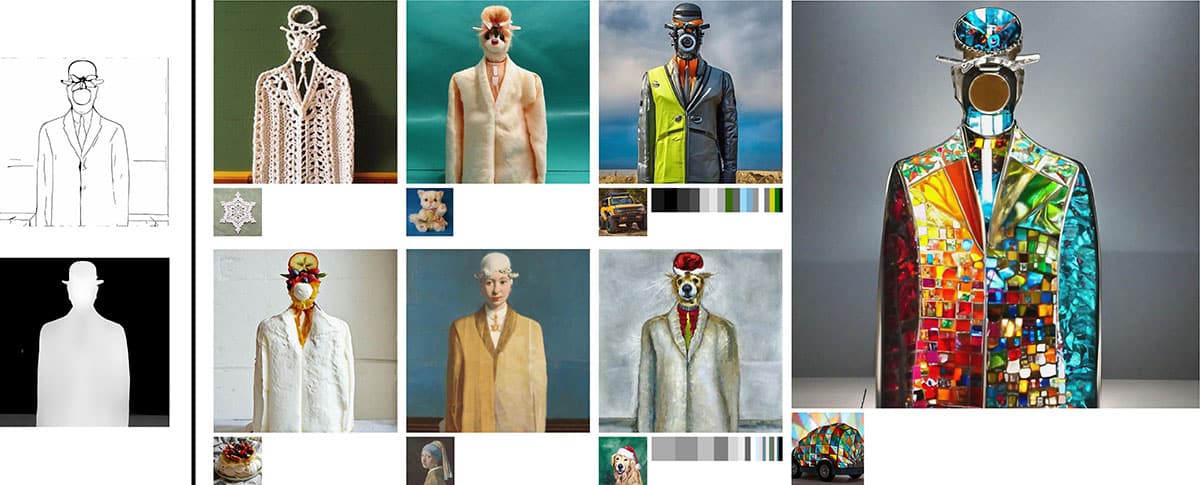
Das Composer-Modell von sechs Forscher:innen der Cornell University soll Kreativen mehr Kontrolle über den Output von generierten Bildern geben
Text-zu-Bild-KIs wie Midjourney oder DALL·E sind bereits extrem gut darin, einen Prompt Wirklichkeit werden zu lassen. Aber um ganz spezifische Details zu erzielen, braucht man doch einige Erfahrung und Geduld.
Composer – ein experimentelles KI-Model einer Forschungsgruppe der Cornell University – könnte das in Zukunft ändern.
Die Maskierfunktion erlaubt, nur bestimmte Bereiche des Bildes neu zu generieren.
Creative Ai, nur besser?
Composer erlaubt Nutzer:innen, wie der Name schon sagt, Bilder zu komponieren. Dazu trainierten die Forscher:innen ihr Modell darauf, unterschiedliche Bildebenen zu erkennen und neu zu kombinieren. Bilder werden also nicht, wie bei gängigen KIs interpoliert, sondern nach unterschiedlichen Bildaspekten neu zusammengesetzt.
Dazu gehören neben Textbeschreibung, Histogramm, Bildstil und einer Depth Map auch die Farbpalette, eine Skizze, eine Funktion, um das Motiv vom Hintergrund zu trennen und eine Maske. Nutzer:innen können dann diese Ebenen nach Belieben kombinieren und so nicht nur endlose Variationen erstellen, sondern auch ganz gezielt ein Detail anpassen, um so das gewünschte Ergebnis zu erhalten – besonders spannend wenn beispielsweise für Social Media eine große Bandbreite an Visuals erstellt werden müsste.
Aktuell befindet sich das Modell noch im Test. In den nächsten Schritten will das Forschungsteam einige Trainingsmodelle veröffentlichen, um schließlich ein funktionierendes Programm auf den Markt zu bringen.
Die Depthmap in Kombination mit einer Texteingabe wie »Realistisches Bild eines Kaktusses« erlaubt Nutzer:innen, exakte Grafiken nach ihren Vorstellungen zu schaffen.Kombiniert man die Depthmap eines Bildes mit der Skizze, lassen sich verschiedene Hintergründe, Farben und Patterns erstellen und weiter durch den Einsatz einer bestimmten Farbpalette oder Interpolation mit anderen Bildern anpassen.Mit Composer lassen sich auch klassischere KI-Tasks erfüllen, wie zum Beispiel der Style-Transfer. Kombiniert mit verschiedenen anderen Composer-Ebenen ergeben sich interessante Effekte.Ganz subtil: Schon die Farbpalette anzupassen kann für starke Variation sorgen
Weiterlesen zum Thema KI und Design
Wir bemühen uns, stets über die neuesten Entwicklungen rund um KI und Design zu berichten. Zum Einstieg in das Thema haben wir einige Artikel zusammengestellt. Bitte beachtet dabei, dass sich die Lage fast wöchentlich ändert und einige der Inhalte nicht mehr aktuell sein könnten.
 Text-zu-Bild-KIs wie
Text-zu-Bild-KIs wie