Auch ohne umfangreiches Hintergrundwissen der Programmiersprache Python oder einem Abschluss in Data Sciences können Kreative eigene Stable Diffusion Modelle trainieren und nutzen. Alles, was man dafür wissen muss, findet ihr in diesem Quickstart Guide.
Wenn erst mal alles lokal funktioniert, kann man Tage und Nächte lang Spaß haben beim Experimentieren mit den detaillierten Einstellungen von Automatic1111 und den vielfältigen unterstützten Trainingsmodellen.
Um Stable Diffusion Modelle mit eigenen Inhalten weiter zu trainieren, muss man im Wesentlichen drei Fragen beantworten.
1. Auf welches Konzept soll das Modell speziell trainiert werden? Sprich: Was soll mein KI-Modell Einzigartiges können?
Als einfaches Beispiel bietet sich das eigene Gesicht an. Porträtgeneratoren wie die Smartphone-App Lensa.ai (die ebenfalls auf Stable Diffusion aufsetzt) waren zu Beginn des Jahres in aller Munde. Lensa kostet aber Geld und bietet keine Einstellungsmöglichkeiten in der visuellen Gestaltung. Mit einem eigenen Modell haben Kreative alle Freiheiten und können mit etwas Übung und Zeit visuell deutlich höhere Qualität erzielen.
Los geht’s: Für Deinen beispielhaften Porträtgenerator benötigst du eine Auswahl von 15-20 Porträtbilder von dir. Perfekt sind verschiedene Perspektiven, einige Bilder mit Schultern und Oberkörper und einige ohne, sowie verschiedene Gesichtsausdrücke. Wichtig: Alle Bilder sollten auf ein Format von 512×512 Pixel zugeschnitten und korrekt benannt sein.
2.Wie trainiere ich mein eigenes KI-Modell?
Eine einfache Möglichkeit ist Dreambooth: Ein von Google entwickeltes System, um generative Modelle individuell weiter zu trainieren. Dieses Training kann lokal auf dem eigenen Rechner laufen, braucht dann aber etwas mehr Technikverständnis und eine wirklich gute Grafikkarte (empfohlen werden min. 24 GB VRAM!).
Wenn du das nicht hast oder diesen Schritt etwas einfacher haben möchtest, kannst du das Training von Modellen online erledigen lassen. Wir verwenden hier für das Dreambooth-Training die etablierte Machine Learning Plattform huggingface.co, es gibt aber noch zahlreiche weitere Anbieter und Möglichkeiten.
Los geht’s: Um Hugging Face zu nutzen, musst du Dir einen kostenlosen Account anlegen. Dann legst du dir einen sogenannten Space für dein Training an. Wenn du nicht alle Settings selbst einstellen möchtest, kannst du einen bestehenden Space kopieren, indem du z. B. »Dreambooth Training« von Multimodal Art aufrufst und auf »Duplicate Space« klickst.
Nach kurzer Zeit steht ein Space für dein Dreambooth-Training zur Verfügung. Um ihn zu nutzen, musst du noch eine GPU online anmieten. Das geht unter Settings und ist nicht kostenlos, aber preiswert. Für dieses Beispiel reicht eine NVIDIA T4 small, diese kostet 60 US Cent pro Stunde Rechenzeit. Die meisten Modelle lassen sich mit den Standardeinstellungen für circa einen US-Dollar trainieren. Dazu musst du die Bilder hochladen.
Einige Einstellungen müssen noch von Hand gemacht oder geändert werden: Zunächst wählst du als dein Konzept im Dropdown »What would you like to train?« »person« aus. Dann als KI Base Model eine Version von Stable Diffusion, für unser Beispiel am besten die Version v1.5, um maximal kompatibel zu sein. Das Wichtigste ist der sogenannte »concept prompt«: Auf welchen Text-Prompt soll das trainierte Modell reagieren, um ein Bildmotiv individuell zu generieren? Hier solltest du möglichst einen Begriff nehmen, der kein allgemein gebräuchliches Wort ist und sich als einzigartiger Name eignet.
Alle weiteren Einstellungen wie »visibility=private« können so bleiben – besonders die Checkbox bei »Automatically remove paid GPU attribution« angehakt lassen, damit du nicht weiter für die GPU bezahlst, nachdem das Training des Modells mit deinen Bildern fertig ist. Jetzt musst du dem zu trainierenden Modell noch einen eigenen Namen geben.
Einmal wird es im Interface von Hugging Face dann noch etwas kompliziert, denn abschließend musst du noch ein sogenanntes Token anlegen. Dazu klickst du auf »Hugging Face write access «, dann auf den »new token« Button, gibst auch dem Token wiederum einen Namen, wählst als Rolle »write« aus und klickst auf »Generate token«. Diesen Token kopierst du in das Feld für »Hugging Face Write Token« und dann kann das Training starten.
Wenn es nach ca. 30 Minuten fertig ist, kannst du bereits direkt auf Hugging Face Bilder mit deinem Modell generieren. Dazu gehst du in deinem Account auf dein Modell. Diese Funktion läuft nicht auf der kostenpflichtigen GPU der Plattform und kostet daher nichts – bietet aber auch wenig Einstellungsmöglichkeiten über das Schreiben von Text-Prompts mit deinem Concept hinaus.
Aber man sieht bereits, dass das Training funktioniert hat: Kein anderes Stable Diffusion Modell auf der Welt kann dein Thema unter diesem Begriff generieren. Um die gestalterischen Möglichkeiten deines Stable Diffusion Modells auszuschöpfen, lädst du dein Modell als .ckpt Datei herunter. Die Datei ist vermutlich einige Gigabyte groß, denn sie enthält ja nicht nur Dein Training, sondern als Grundlage das gesamte antrainierte »Wissen« von Stable Diffusion in der Version 1.5.
3. Wie arbeite ich mit meinem eigenen KI-Modell?
Es gibt verschiedene Möglichkeiten, Stable Diffusion Modelle auf dem eigenen Rechner zu nutzen mit Einstellungsmöglichkeiten wie positive und negative Prompts, Batch Count und mehr. »Automatic1111« ist wohl das zur Zeit bekannteste Community User Interface für Stable Diffusion und es gibt für Windows und MacOS einen automatische Installer – wir verwenden beispielhaft ein Macbook mit Apple Silicon (M1 oder M2). Es geht aber auch ein WindowsPC mit einer Nvidia-Grafikkarte mit mindestens 4GB Speicher.
Los geht’s: Zunächst benötigst du den Paketmanager »Homebrew« für MacOS. Dieser kann kostenlos hier heruntergeladen werden: https://brew.sh/. Du installierst ihn mit dem Terminal-Befehl (beginnt mit dem [ und endet mit ] ):
Damit funktioniert »Homebrew« bzw. der Befehl [ brew ] wie gewünscht und du musst dich um die weiteren Installationspakete nicht selbst kümmern. Wenn du mehr über Homebrew wissen möchtest, kannst du [ brew help ] im Terminal eingeben oder die Dokumentation im Browser lesen: https://docs.brew.sh.
Nun installierst du mit Homebrew alle erforderlichen Pakete, indem du den folgenden Befehl ausführst:
Nun liegt alles bereit in deinem Benutzer-Ordner in einem neuen Ordner namens »stable-diffusion-webui«. Diesen benötigen wir im nächsten Schritt. Du kannst ihn im Finder öffnen oder mit diesen beiden Zeilen:
[ cd stable-diffusion-webui ] [ open . ]
Du kannst jedes Stable Diffusion-Modell lokal benutzen, das du im Ordner “models” in »Stable-diffusioni« ablegst. Dort liegt zu Beginn nur eine leere Text-Datei namens »Put Stable Diffusion checkpoints here.txt«. Ein guter Start ist das Original Stable Diffusion 1.5 wiederum von HuggingFace. Klicke in HuggingFace auf das Tab für Dateien und Versionen und dann neben »v1-5-pruned.ckpt« auf den kleinen Pfeil, der sich direkt neben der Dateigröße in derselben Zeile befindet.
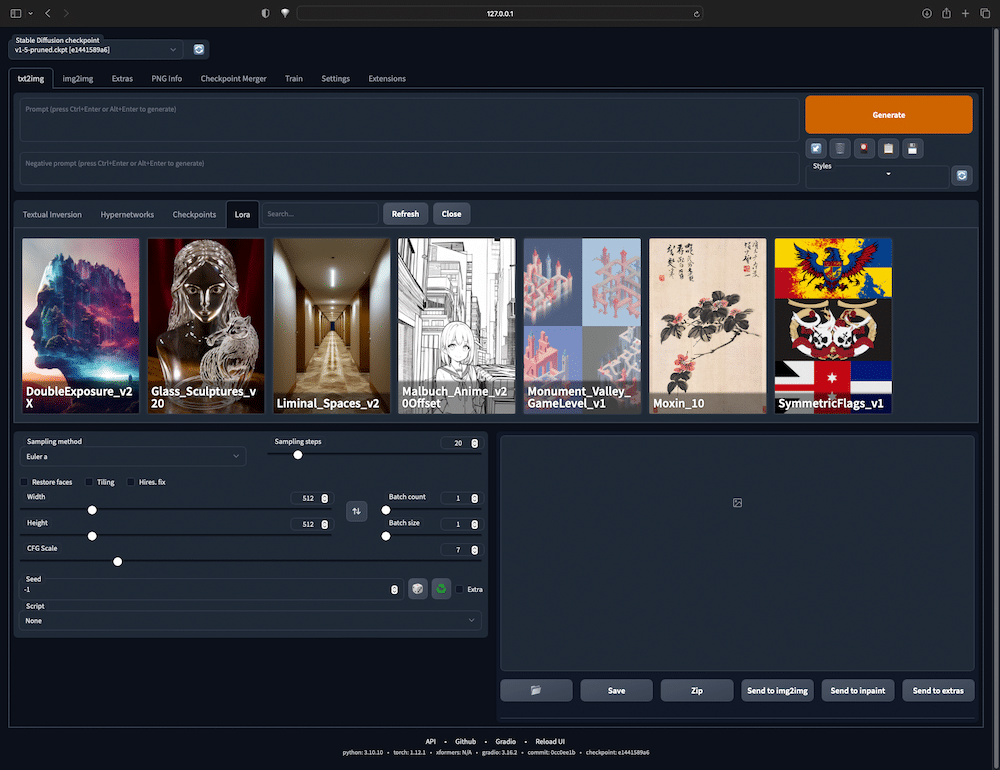
Vor allem solltest du natürlich dein eigenes Modell hier abgelegen! Alle Modelle und Versionen stehen dir in »Automatic1111« ganz links oben in einem Dropwdown-Menü zur Auswahl. Neben checkpoint files (.ckpt) gibt es auch andere Modelle aus anderen Trainingstechniken, wie Low-Rank Adaptation Modellen (LoRA) und embeddings (Textual Inversion). Diese files sind kleiner, ebenso allerdings die Möglichkeiten der Bildkontrolle für Kreative. Automatic1111 kann mit allen Formaten umgehen. Du legst die Dateien einfach in die entsprechende Unterordner »embeddings« oder »Lora« im Ordner »stable-diffusion-webui« ab und Automatic1111 zeigt sie im Nutzerinterface dann automatisch mit an.
Wenn der Modelle-Ordner befüllt ist, kannst du das User Interface von Automatic1111 öffnen. Das passiert noch einmal im Terminal:
[ ./ webui.sh ]
Beim ersten Start werden nochmal einige Packages wie PyTorch nachgeladen, die Stable Diffusion benutzt. Daher kann das erste Öffnen etwas dauern – danach geht es schneller. Wenn alles bereit ist, erscheint im Terminal »Running on local URL: http://127.0.0.1:7860«. Die URL http://127.0.0.1:7860 kannst du nun in einen beliebigen modernen Browser wie Chrome, Safari oder Firefox kopieren und darin komfortabel und lokal mit einem grafischen User Interface text2img und img2img zur Generierung von Bildern nutzen.
Mit dem auf dein Gesicht trainierten Beispiel-Modell kannst du nun beliebig viele Porträtbilder in beliebigen Stilen erzeugen. Funktionen wie »Restore faces«, um Augenfehlstellungen und Asymmetrien bei Porträts automatisch zu korrigieren, helfen dabei bessere Bilder zu generieren als z.B. die eingangs erwähnte App Lensa.ai. Es braucht lediglich Ideen und Übung. Inspirationen für visuelle Stilistik und Ästhetik und die entsprechenden Textprompts findest du z. B. auf Webseiten wie lexica.art oder prompthero.com.
Das Experimentieren und Üben mit Einstellungen und Prompts ist jetzt kein Problem mehr, da alles lokal auf deinem Rechner passiert, du keine Credits mehr nachkaufen musst und die generierten Bilder nicht automatisch in der Cloud gespeichert sind. Darüber hinaus sind noch weitere Funktionen, auch für ganz andere Arten von Bildmotiven, bereits installiert – z. B. »Tiling«, um nahtlose Texturen zu erzeugen. Und du kannst im WebUI im Tab »Extensions« noch weitere Funktionalitäten hinzufügen. Happy Prompting!
Mehr zum Thema »Zusammenarbeiten mit KI« lest ihr in PAGE 5.2023:
Designmethoden und -prozesse in der Praxis ++ Comeback der Pixelschriften ++ ENGLISH SPECI-AL Jessica Walsh ++ Designsystem für Scania ++ Making-of: UX-Redesign bei Wikipedia ++ Um-weltfreundlich verpacken: Tipps & Ideen ++ Creative AI in Agenturen